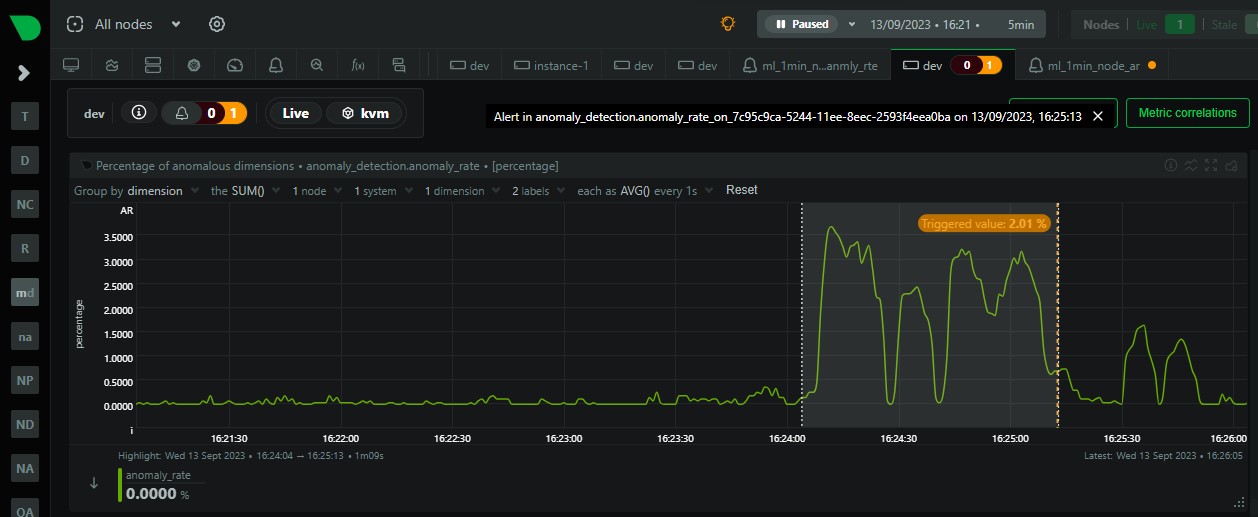
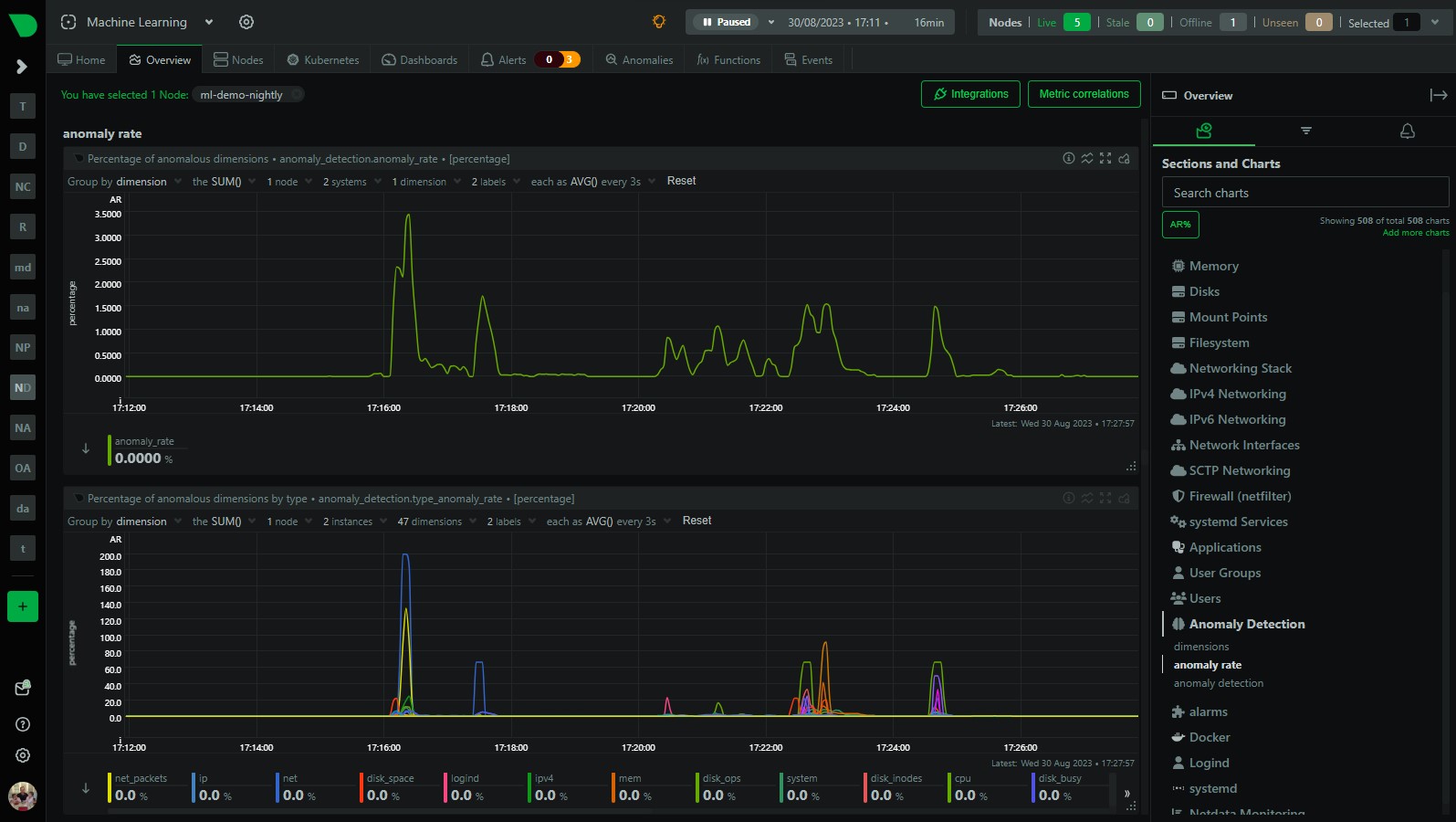
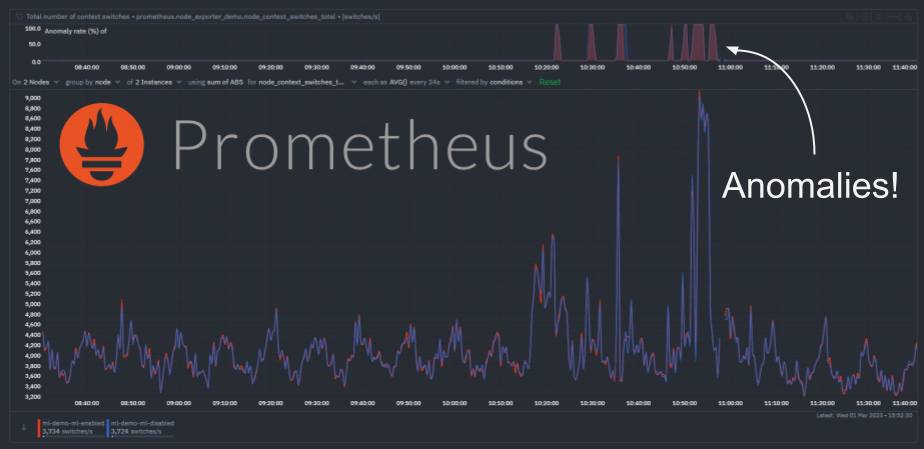
Effective system monitoring is non-negotiable in today's complex IT environments. Netdata offers real-time performance and health monitoring with precision and granularity. But the key to harnessing its full potential lies in the optimization of your setup. Let’s ensure you are not just collecting data, but doing it in the most optimal way while gaining actionable insights from it.
Netdata Best Practices: Optimizing Your Monitoring Setup
· 13 min read